What RMSNorm Actually Does (And Why You Can't Replace It With a Point-wise Norm)
An empirical dissection of normalization in transformers.
The question
The DyT paper (Zhu et al., 2025, Transformers without Normalization) proposes replacing RMSNorm with , a purely element-wise function. They show it works at LLaMA 7B to 70B scale.
We asked: what is RMSNorm actually doing that a point-wise function can’t? Is it the rescaling? The squashing? Or something deeper?
We ran 20+ experiments on 360M-param transformers, dissecting every component of normalization. Here’s what we found.
A tale of two normalizers
Before the experiments, let’s set up the math. RMSNorm and DyT both take a vector of dimension and produce an output of the same shape. But their internal mechanics are fundamentally different.
RMSNorm computes a global statistic over all channels, then divides:
Every output channel sees the same denominator , which depends on all input channels. This is the “coupling”: channel ‘s output depends on channels through the shared denominator.
DyT (Zhu et al., 2025) applies a scalar function independently to each channel:
Channel ‘s output depends only on . No channel ever sees its neighbors. This is “point-wise”: each dimension is processed in isolation.
The question is whether this difference matters for training.
The forward gain problem
Define the forward gain of a normalizer at input scale :
This measures how much the normalizer amplifies (or attenuates) the input magnitude.
Theorem 1 (Point-wise gain is bounded). For any point-wise norm with and finite :
Proof. Taylor-expand: . Then , so the ratio converges to as .
The gain is a fixed constant determined by the function’s local slope at zero. It does not depend on . It cannot adapt to the input magnitude.
Theorem 2 (RMSNorm gain is unbounded and adaptive). For RMSNorm with :
Proof. when . So while . Ratio .
RMSNorm’s gain is inversely proportional to input scale: small inputs get amplified more, large inputs get attenuated. This is automatic, per-token, and requires no learning.
The fundamental trade-off. A point-wise function cannot have both:
- (a) unbounded gain at small inputs (needs )
- (b) bounded output at large inputs (needs saturation, which forces finite)
RMSNorm sidesteps this because its gain is data-dependent (), not a property of a fixed scalar function. The denominator’s sum over channels is what makes this possible.
What this means at init
With standard GPT-2 init (), the residual stream entering block 0 has std . Plugging into the gain formulas:
- RMSNorm: . Output std .
- DyT (): . Output std .
The two layers receive signals whose magnitudes differ by a factor of 50, and the consequences cascade through every downstream operation in the block.
Consider what attention does with these inputs. After the input is projected to queries and keys, the attention logit for a (query, key) pair is the dot product . With independent components of standard deviation , this dot product has variance proportional to , so the spread of attention logits across positions scales as . RMSNorm feeds in , producing logits with spread, exactly the regime softmax was designed for. DyT feeds in , producing logits with spread , roughly 2500 times smaller. After softmax, those logits are indistinguishable, and the attention distribution collapses to nearly uniform over all positions in the context.
A nearly uniform attention pattern means each token receives essentially the average of its context, weighted equally. There is no selection happening, no information being routed; the attention output is approximately a constant vector independent of the query. Gradients flowing back through this layer have very little structure to learn from, because the layer is computing a near-constant function of its input regardless of the parameter values. The MLP downstream sees a similarly tiny input () and, for the same reason, produces a near-linear output with no useful nonlinearity engaged. Both sublayers contribute almost nothing to the residual stream.
Now consider the residual update: . If the block output is essentially zero, the residual stream just propagates the embedding layer’s activations forward, layer after layer, unchanged. The model effectively reduces to a linear function of the token embeddings followed by the unembedding head. In practice, training converges to a loss equal to the entropy of the unigram distribution: the model has learned to predict tokens based on their frequency alone, with no contribution from context. This is the “embedding-only attractor” we’ll see numerically below at loss 7.54.
Result 1: Point-wise norms universally fail at narrow width
We replaced RMSNorm with six different point-wise functions at width 1024 (24 layers). Every single one converges to the exact same loss, to four decimal places.
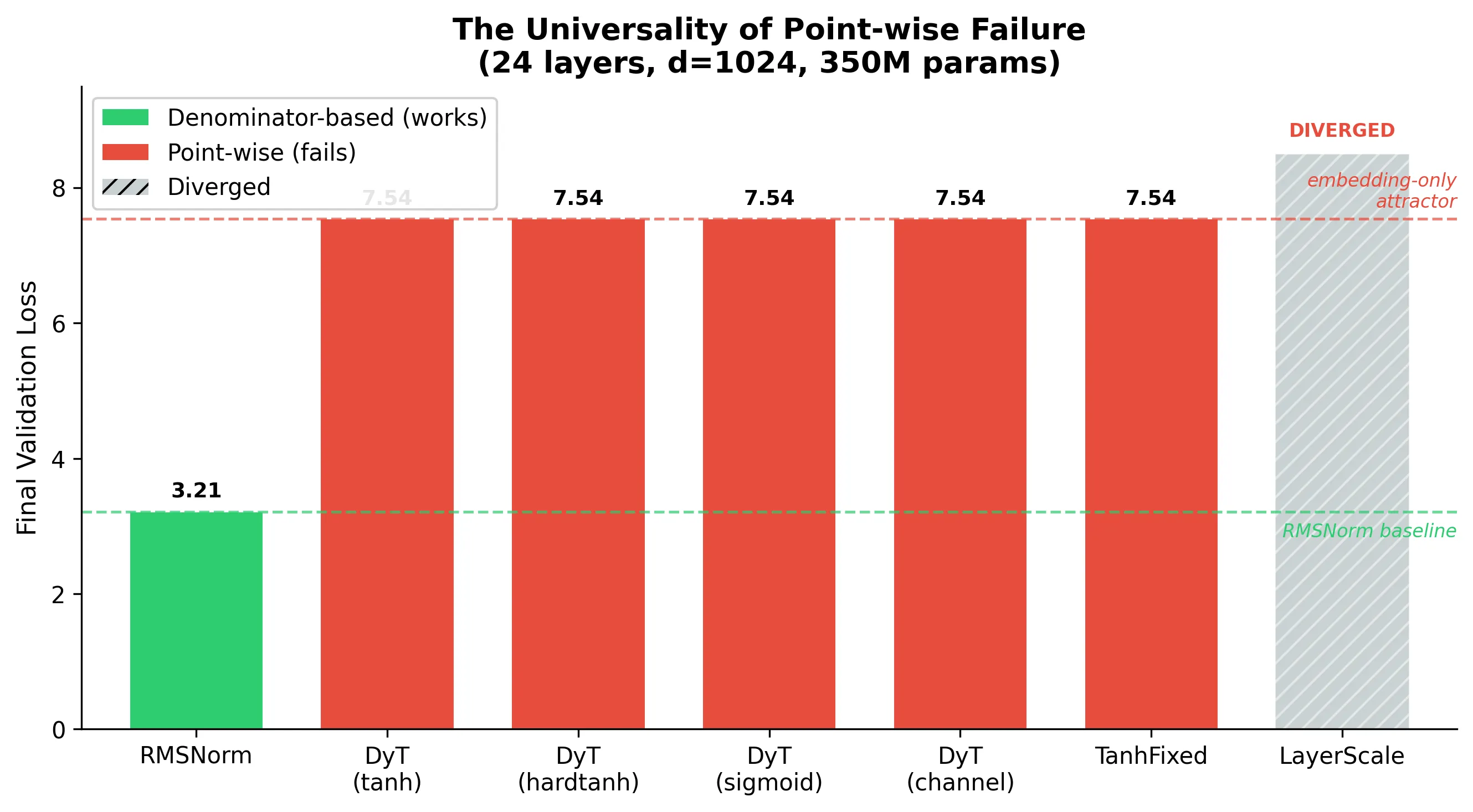
| Point-wise variant | Final loss | |
|---|---|---|
| DyT (tanh) | 7.5422 | |
| DyT (hardtanh) | 7.5422 | |
| DyT (sigmoid) | 7.5424 | |
| DyT (per-channel alpha) | 7.54 | |
| TanhFixed (no alpha) | 7.54 | |
| LayerScale (linear) | NaN (diverged) | |
| RMSNorm | 3.21 |
The 4-decimal agreement across five different squashing functions is the empirical confirmation of Theorem 1: since all have , they all produce the same gain, the same dead-block pathology, and the same embedding-only attractor at 7.54. The specific shape of is irrelevant.
Result 2: Width matters, but why?
Same param count (~360M), different shape:
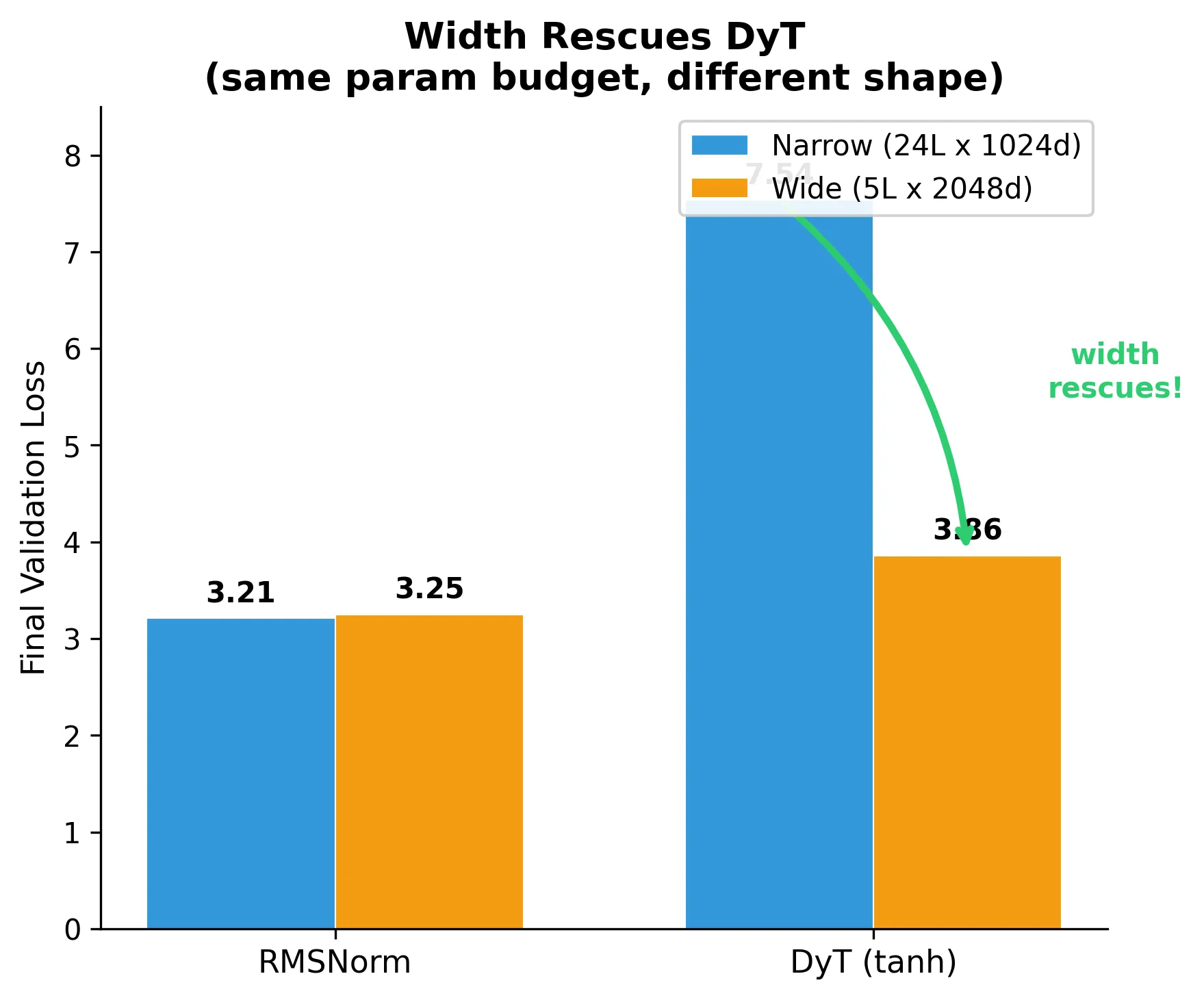
| Config | RMSNorm | DyT | Gap |
|---|---|---|---|
| Narrow (24×1024) | 3.21 | 7.54 | 4.33 |
| Wide (5×2048) | 3.25 | 3.86 | 0.61 |
Doubling the width closes the gap by a factor of 7. To see why, we have to track what happens to the residual stream’s magnitude as we move through layers, and then ask when (if ever) that magnitude grows large enough to push DyT out of its useless linear regime.
The signal scale grows layer by layer. At every block, the residual stream gets an additive update: . If the block’s output is independent of (a reasonable approximation at init), then variances add: . So the std of the residual stream grows roughly as in the number of layers, assuming each block contributes a constant amount.
But how much does each block contribute? That’s where width enters. Each sublayer ends in a projection conventionally named c_proj. In attention, it is the output projection that maps the concatenated head outputs back to ; in the MLP, it is the second linear layer that maps the hidden activations back down to . In both cases c_proj is the layer that writes the sublayer’s result into the residual stream, so its weight scale directly controls how large each block’s contribution to is at init.
And in our setup the init is scaled with depth, exactly as written. We use the standard nanoGPT GPT-2 init, which singles out the residual-writing projections: only c_proj weights get the depth-dependent rescaling, drawn from , while every other linear layer uses a flat . The factor is there to keep the residual-stream variance from growing unboundedly with depth — deeper models get smaller block outputs at init by construction. Two effects then compound:
c_projinit std shrinks with depth. For the deep model (): . For the shallow model (): . The shallow model’s block-output weights start about 2.2x larger.- Width amplification through MLP. The block’s output is roughly , and the activations are themselves a function of -dimensional inputs. Sum-over-channels gives a factor. Width 2048 gives a boost over width 1024.
Multiplying these gives the wide model’s residual stream growing roughly 3x faster per layer in std. Add the layer-count effect (), and after a handful of layers the signal at width 2048 has grown into the range where exceeds the linear regime of (roughly ). Once you’re in the bend region of , the derivative starts to differ meaningfully from the constant , gradients carry information about , and the block starts to actually learn.
At width 1024 with 24 layers and standard init, the residual stream never gets large enough within the available depth. The signal stays inside the linear regime of from block 0 to block 23, every block remains “dead,” and the embedding-only attractor wins. At width 2048, the same arithmetic puts the signal into tanh’s nonlinear region by mid-network, and training proceeds, although still with a 0.6-nat handicap relative to RMSNorm (because the early layers are still wasted, and the rescue is partial).
This is also why the DyT paper’s claims hold at LLaMA scale: by width 4096+ and with their tuned , the signal escapes the linear regime almost immediately. The pathology we see at width 1024 is invisible from a 7B-and-up vantage point.
The backward pass: where the real action is
Everything above is about the forward pass (gain, signal scale). But our most surprising finding is that forward gain alone is not sufficient. To see why, we need to look at what happens during backpropagation.
The Jacobian of RMSNorm
For where , the Jacobian decomposes into two terms:
The diagonal term is what provides the 50x forward gain. It scales each channel by , the same amplification we computed above.
The coupling term is a rank-1 matrix . It projects out the component of the upstream gradient that is aligned with the current input direction . In other words, it forces the gradient to be orthogonal to .
For DyT, the Jacobian is purely diagonal:
Zero off-diagonal entries. No coupling. No projection.
Measured Jacobian norms
We computed these numerically at init (input std , ):
| Width | Norm | |||
|---|---|---|---|---|
| 1024 | RMSNorm | 1602 | 50 | 1601 |
| 1024 | DyT | 32 | 0 | 32 |
| 2048 | RMSNorm | 2259 | 50 | 2258 |
| 2048 | DyT | 45 | 0 | 45 |
RMSNorm passes ~50x more gradient. DyT’s coupling is identically zero. The coupling term itself is only ~3% of the diagonal (50/1602). We’ll come back to why this 3% matters so much.
Result 3: The denominator is everything
To isolate what about RMSNorm matters, we tested ten alternatives:
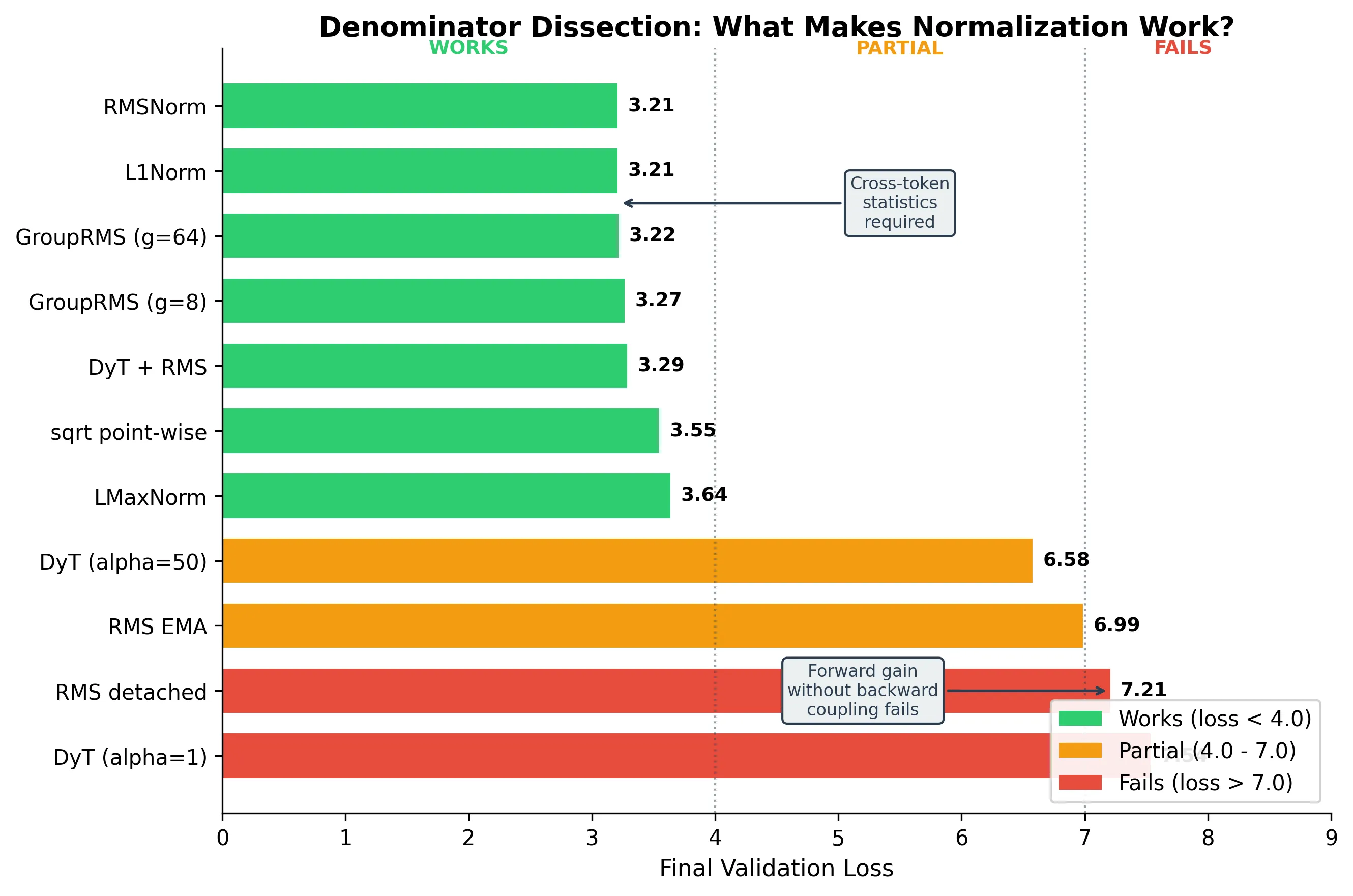
| Norm | What it tests | Loss | Works? |
|---|---|---|---|
| RMSNorm | Baseline | 3.21 | ✓ |
| L1Norm () | Does it need to be L2? | 3.21 | ✓ |
| GroupRMS (8 channels) | How much coupling? | 3.27 | ✓ |
| DyT+RMS denom | Give DyT back the coupling | 3.29 | ✓ |
| sqrt pointwise () | Infinite gain, no coupling | 3.55 | ✓ |
| LMaxNorm () | Weakest aggregate | 3.64 | ✓ |
| DyT (50x fixed gain) | Match RMSNorm’s init gain | 6.58 | ✗ |
| RMS detached (no backward grad) | Remove coupling, keep gain | 7.21 | ✗ |
| RMS EMA (running average) | Remove per-token adaptation | 6.99 | ✗ |
| DyT (standard) | No gain, no coupling | 7.54 | ✗ |
Three findings:
Finding 1: Any dim-aggregate works. L1Norm matches RMSNorm exactly. The choice of L2 in RMSNorm is historically contingent, not mathematically necessary.
Finding 2: Even 8 channels suffice. GroupRMS with groups of 8 (out of 1024) already matches full RMSNorm. You need ~0.8% of channels coupled.
Finding 3: Fixed 50x gain fails. DyT with has identical forward gain to RMSNorm at init. Still fails (6.58). This is the first hint that the forward story is incomplete.
Result 4: The backward coupling is load-bearing
This is the killer experiment.
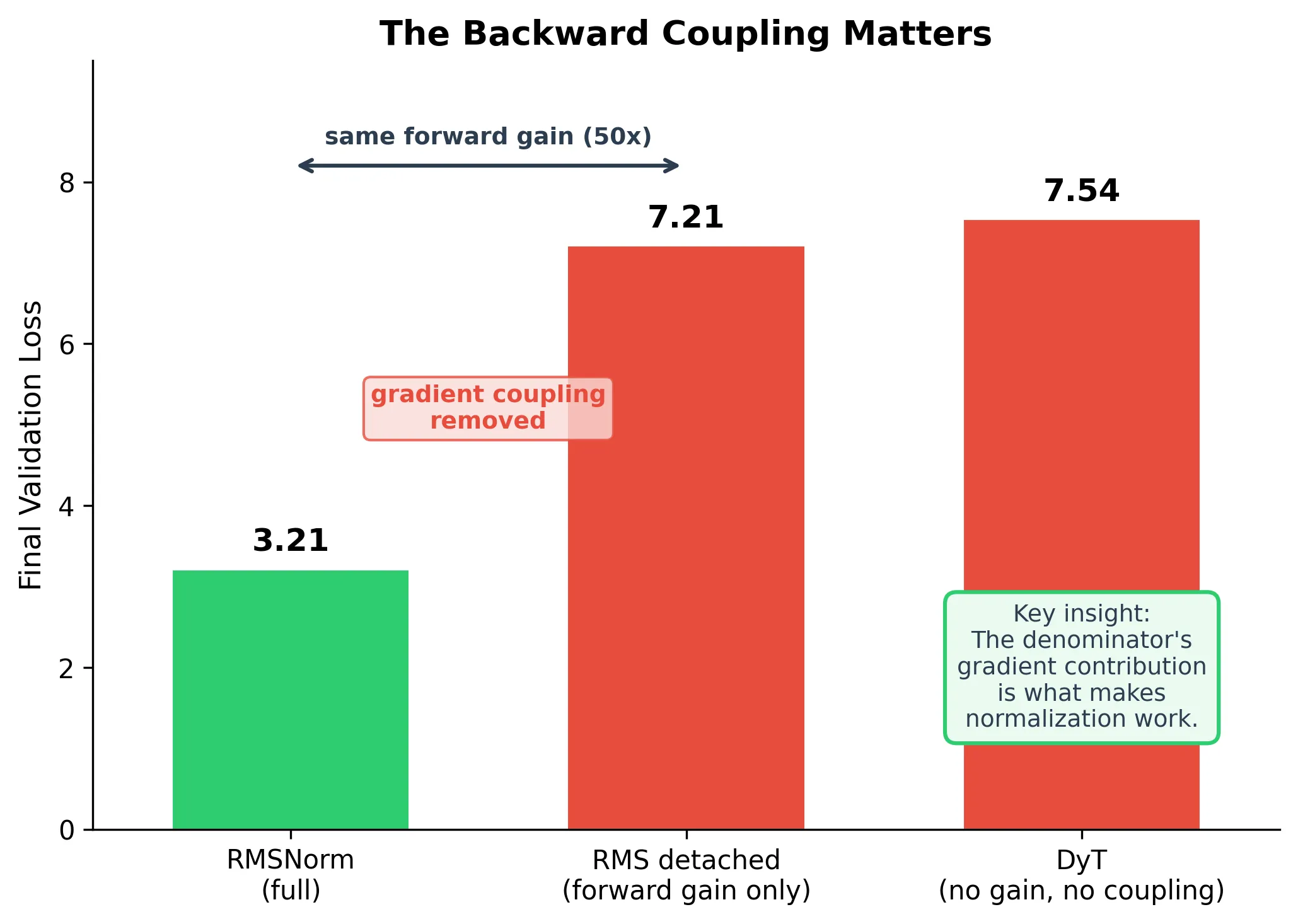
RMS detached: we compute exactly as in RMSNorm, but call .detach() on the denominator. The forward pass is byte-for-byte identical. The activations are identical. The only difference is that during backpropagation, no gradient flows through .
| Variant | Forward gain | Backward coupling | Loss |
|---|---|---|---|
| RMSNorm | 50x (adaptive) | Yes | 3.21 |
| RMS detached | 50x (adaptive) | No | 7.21 |
| DyT (Zhu et al., 2025) | 1x (fixed) | No | 7.54 |
Same forward computation. Same activations. Same scale. +4.0 nats.
Removing the gradient through the denominator kills training. The full gradient of RMSNorm is:
The .detach() removes the second term. That second term, the cross-channel coupling through the shared denominator, is the entire difference between “trains” and “broken.”
What the coupling term does mechanistically
The coupling term does three things:
1. Gradient orthogonalization. The term is proportional to , which means it subtracts the component of that points along . After this subtraction: exactly. The gradient is forced to be orthogonal to the current activation. This prevents “just scale up what you already have” updates and forces the network to explore new representational directions.
2. Cross-channel information flow. The inner product aggregates the loss signal across all channels into a single scalar, then broadcasts it back to every channel (weighted by ). If channel 73 has zero local gradient but channel 500 has a strong signal, channel 73 still gets an update via this broadcast.
3. Implicit rank regularization. By projecting out the -direction from every gradient update, the coupling term prevents the residual stream from collapsing into a low-rank subspace. Without it, the optimizer preferentially grows the existing dominant directions (since those have the largest gradients), leading to rank collapse.
The minimal requirements for normalization
From 20+ experiments, the complete decomposition:
| Property | Essential? | Evidence |
|---|---|---|
| Specific norm (L2 vs L1 vs L∞) | No | L1 = RMSNorm |
| Full-dim aggregate (all 1024 ch) | No | 8 channels suffices |
| Forward gain at init | No (surprisingly) | detached has gain, still fails |
| Backward gradient coupling | YES | detached proves this |
| Per-token adaptation | YES | EMA proves this |
The minimal effective norm is any function that (1) aggregates a statistic across channels of the hidden dimension, (2) uses it to scale the output, (3) passes gradients through the aggregation, (4) does so per-token.
L1Norm () is the simplest instantiation, and it’s computationally cheaper than RMSNorm (no squares, no sqrt).
The theoretical escape hatch
There is ONE point-wise function that partially works: .
It achieves loss 3.55, only +0.34 vs RMSNorm, despite having zero channel coupling. Why? Its derivative at zero is infinite: . This gives it unbounded gain at small inputs, sidestepping the bound in Theorem 1 (which assumes finite ).
But it can’t fully match RMSNorm because:
- Its gain is a function of alone.
- RMSNorm’s gain is a function of all channels jointly.
- When channels have heterogeneous magnitudes (common: attention sinks, outlier features), RMSNorm adapts to the collective scale; sqrt-pointwise treats each channel independently.
This confirms that coupling is not strictly necessary if you have unbounded gain, but coupling provides something that no per-element gain function can replicate: awareness of the full activation vector’s geometry.
Result 5: Resolving the coupling paradox
The Jacobian coupling term is only ~3% of total gradient norm. Yet removing it (detached) costs 4 nats. How can 3% matter this much?
The dose-response curve
We implemented RMSNormPartialCoupling, a variant where the backward coupling strength is continuously tunable. Mathematically, the effective gradient becomes:
At this is full RMSNorm. At this is detached. We swept :
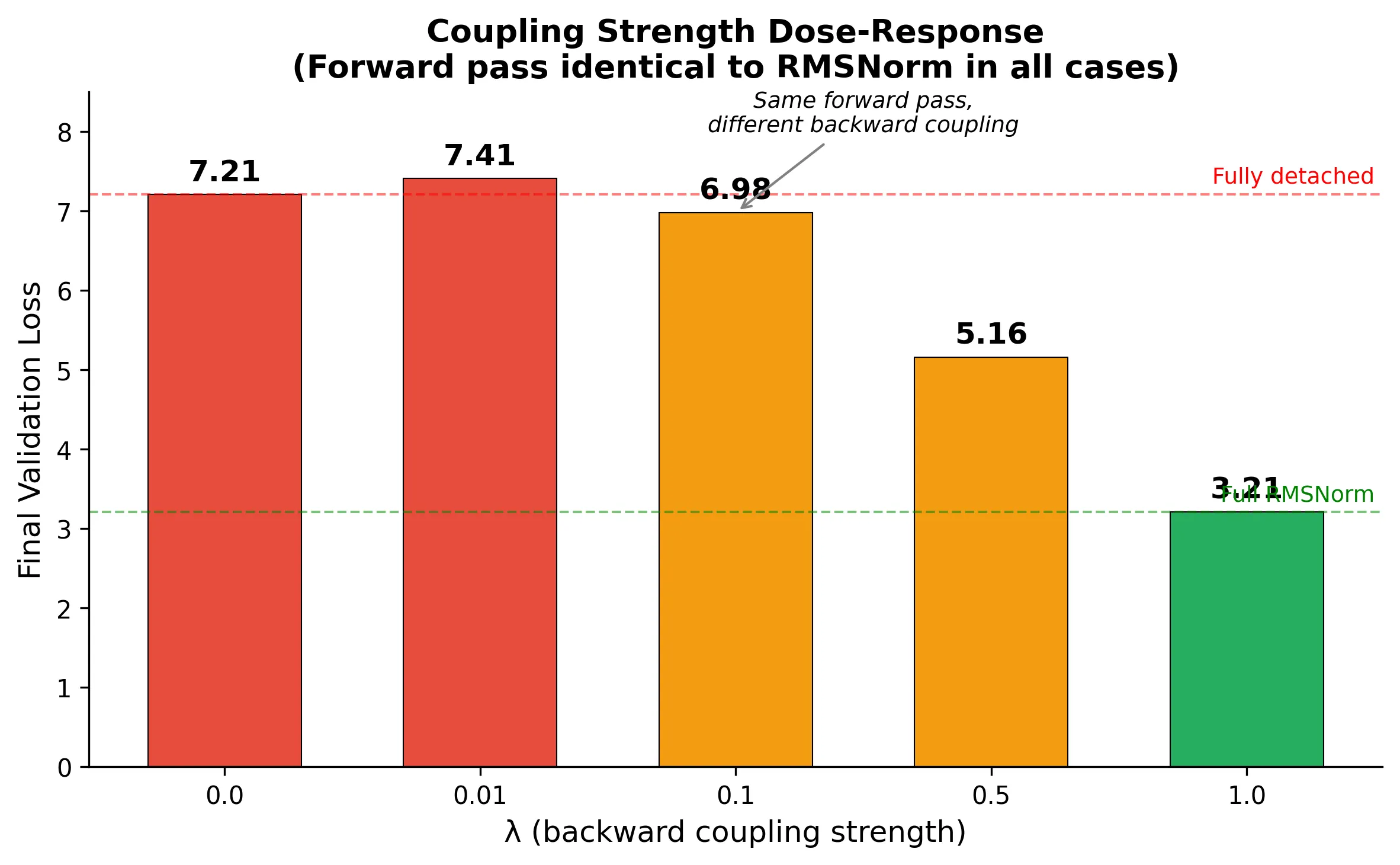
| (coupling strength) | Final loss | Status |
|---|---|---|
| 0.0 (detached) | 7.21 | broken |
| 0.01 | 7.41 | broken |
| 0.1 | 6.98 | broken |
| 0.5 | 5.16 | impaired |
| 1.0 (full) | 3.21 | works |
Not a phase transition, but a smooth degradation. You need nearly full coupling () to maintain training quality.
Why: the coupling is a thermostat for gradient direction
We measured two quantities from the trained models:
![]()
| Metric | RMSNorm () | Detached () |
|---|---|---|
| Effective rank (attn c_proj) | 727 | 158 (4.6x collapse) |
| Effective rank (mlp c_proj) | 936 | 195 (4.8x collapse) |
| 0.0000 | 0.0084 |
1. With coupling: gradient is perfectly orthogonal to activation. , not approximate, exact to four decimals. This is mathematically guaranteed: the coupling term subtracts exactly the -component of the gradient.
2. Without coupling: rank collapses 5x. When the gradient can align with the activation, the optimizer only learns to scale existing representations. It cannot explore new directions. Weight matrices lose effective rank. Expressivity collapses.
Resolving the paradox
The coupling term is 3% of gradient magnitude per step. But it operates in a specific rank-1 subspace (the -direction) that would otherwise receive zero corrective signal. Its importance is not about size; it’s about being the only source of orthogonality enforcement in the system.
Each optimizer step drifts the gradient slightly toward alignment with (gradient descent naturally amplifies existing patterns). The coupling term pushes back, a continuous correction. At full strength (), drift is exactly canceled: . At , half the correction is missing; drift accumulates over 6860 steps into moderate rank collapse (+2 nats). At , the correction is negligible and full rank collapse ensues.
The analogy: a thermostat uses a tiny fraction of a room’s thermal energy, but running it at 50% power makes the room uninhabitable. The coupling is normalization’s thermostat for gradient direction, a small continuous correction that prevents catastrophic drift.
Summary: What makes RMSNorm work
RMSNorm provides exactly two things that point-wise functions cannot:
1. Data-dependent forward gain (): automatically amplifies small inputs and attenuates large ones, keeping the signal in a useful range without any learning. Point-wise functions have fixed gain that cannot adapt.
2. Backward gradient coupling: the off-diagonal Jacobian term projects out the -aligned component of the gradient, maintaining perfect orthogonality between updates and current activations, preventing rank collapse. Point-wise functions have zero off-diagonal Jacobian by construction.
Of these two, the backward coupling is the more surprising and more essential finding. Forward gain can be approximated by other means (wider init, sublinear squashers, high ). Backward coupling cannot be replicated by any point-wise operation; it requires reading a cross-channel statistic and passing gradients through it.
Implications
-
Don’t use DyT (Zhu et al., 2025) below 2B params. The paper’s claims hold at width , not below. At typical small-LLM widths (1024 to 2048) DyT either fails or underperforms significantly.
-
Normalization’s value is NOT “rescaling.” It’s the backward gradient coupling through a per-token channel-aggregate. Forward gain helps but is insufficient alone.
-
The coupling is a direction regulator, not a magnitude effect. It maintains exact gradient-activation orthogonality, preventing rank collapse. 3% of gradient norm, 5x of effective rank, 4 nats of final loss.
-
If you want cheaper normalization, use L1Norm (); it matches RMSNorm at lower compute cost (no squares, no sqrt). Or GroupRMS with small groups.
-
If you want truly norm-free training, you need a different mechanism for per-token cross-channel gradient flow. Spectral normalization of weights (-Reparam) or nGPT-style hypersphere constraints are candidates; they achieve coupling through the weight matrix rather than an activation normalization layer.
Experiments: 360M GPT, 20 TPP (7.2B tokens FineWeb-Edu), 8×B200 DDP, AdamW lr=3e-4.
Reference: Zhu, J., Chen, X., He, K., LeCun, Y., & Liu, Z. (2025). Transformers without Normalization. arXiv:2503.10622.